下面详述了英特尔通过集成面向制造物联网的大数据分析和技术获得了一些突破性成就和发现。
试点计划成效:
使用案例 1:通过监控和分析设备参数值并在部件发生故障之前及时更换,减少不必要的产能损失。
背景
自动测试装置(ATE)是专门用于在不同设备上执行测试的机器,这些设备被称作被测设备(DUT)。ATE 使用控制系统和自动化信息技术快速执行测试,测量并评估被测设备。11 ATE 系统连接到称为处理工具的自动更换工具上。该工具能够物理更换测试接口单元(TIU)上的被测设备,以便接受该装置的测试。
问题陈述
有缺陷的测试接口单元将会错误地将良品分类为次品,会对英特尔制造运营成本造成负面影响。有缺陷的测试接口单元会导致对被测设备进行错误分类,包括拒绝良品。英特尔制造部门的目的是检测潜在的 TIU 缺陷,以便及时修理或更换单元,防止它们被错误分类。如果有缺陷的测试接口单元将良品错误分类为次品,该单元将作废。在定期预防性维护期间,一些即便仍然运转正常的组件也会使用备件更换,以避免发生此类问题。
成效和优势
分析功能可在现有工厂联机流程控制系统触发之前,预测出高达 90% 的潜在测试接口单元故障。在此处的情况下,这可帮助及时更存在缺陷的 TIU 以免造成过度拒绝良品,将产能损失降低了 25%。
此外,英特尔还减少了在预防性维护过程中提前更换尚未故障的备件的需求,从而预计可以降低 20% 的备件成本。
使用案例 2:通过在焊球焊接设备中消除和减少错误焊球装配情况降低产能损失
背景
焊球焊接模块是为基片表面涂抹焊膏的部件。焊球被放置到焊球焊接表面,然后焊膏将其固定在相应位置上。整个封装通过一个回流焊炉,将在其中融化基片表面上的焊膏和焊球。
焊球被真空吸附到贴装头的小孔上。系统将检查该贴装头上的焊球是否过多或缺失。当贴装头与基片对齐时,焊球被放置在基片的焊膏上。释放焊球后,将检查贴装头上是否残留有任何焊球。最后,摄像头成像系统将检查基片上是否缺失焊球或焊球位置是否存在偏移。
问题陈述
缺失焊球的单元为有缺陷的材料,会造成产能损失。多种场景会导致单元缺失焊球,包括真空压力不足等。
成效和优势
通过可视化处理传感器读数并将其与各种机器数据和执行系统数据进行关联,英特尔成功降低了产能损失,优化了维护成本,并避免了设备突然宕机。这可帮助技术人员主动解决问题,朝着创建预测维护功能而努力。
使用案例 3:使用图像分析确定良品或次品
背景
机器视觉设备是一种模块,可筛选单元并将其分类为良品和边际单元。良品将传送到加工流程,而边际单元将接收制造专员的检查并确定其优劣。该手动流程较为耗时。
问题陈述
人工检查并分类边际单元的流程非常繁琐,有时需要约8 小时才能成功将边际单元与真正的不良品隔离。
这是因为单元送达操作员、然后传送到隔离模块、最后进行隔离比较费时。图像分析可帮助迅速识别检测模块检测到的不良品。
成效和优势
机器视觉设备模块中记录的边际图形经过预处理。每一张图像都是非结构化数据,需要修改尺寸、剪裁并转化为灰度模式,然后将每个像素转化为二进制格式。此流程的下一阶段涉及特征选择,非结构化图像将由一系列不同的值定义。然后,将这些值赋予各种机器学习算法,用于区分真正不良品和边际不良品。
图像分析缩短了从大量边际单元中分离真正不良品的时间。图像分析确认不良品的速度大约比人工方法快10倍。
数据流
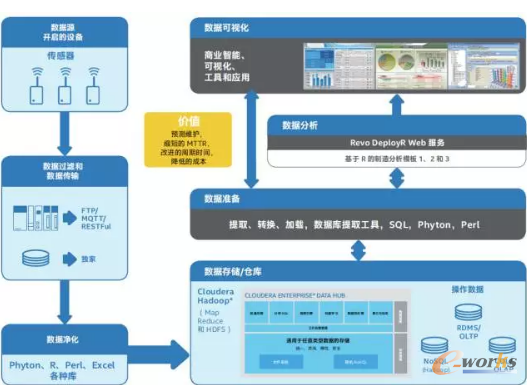
图4 高级数据流
图4显示了上述使用案例中的数据如何传输。
基于英特尔凌动处理器的网关将实时获取的机器数据和传感器数据发送至大数据分析服务器(BDAS)。例如,焊球焊接模块的机器数据通过机器界面端口收集,来自模拟传感器的机器数据以数秒数 MB 的速度进行流传输。
· 收集到的所有工厂数据都存储在 Hadoop* 中。以下不完全列表显示了使用 Hadoop 的现有功能可实现的可能性:
- HTTP:大数据分析服务器展示一个支持对 HDFS 进行操作的经验证的 REST HTTP 端点。
- Apache Sqoop* 提供了连接工具, 用于将非 Hadoop 数据存储(如关系数据库和数据仓库)中的数据迁移至 Hadoop。
- Flume* 能够接收持续的日志数据。
·本部分上述使用案例中的特定数据格式为逗号分隔值(CSV) 文件或原始图像。尽管 Hadoop 生态系统包含多种数据摄入途径(如上所述),但一些工厂机器的网络传输能力有限,要求通过定制工程向 HDFS 提交数据:
- FTP:物联网网关拥有一个 FTP客户端,定期连接到大数据分析服务器,并将最新获取的数据直接传输到 HDFS。也可以根据实时数据流和分析要求使用 MQTT 和 REST 等其他数据流协议。
- CIFS 共享(Windows 共享):大数据分析服务器提供了一种 Windows/CIFS 共享目录,网关 可将文件复制到该目录中。
·CSV 文件被使用 Pig 直接导入HBase*,而原始图像会先使用计算机视觉技术和 map-reduce 任务进行预处理,生成图像的文本数据表示。
·根据操作要求,数据将在三个数据 库中的一个进行存储:NoSQL (Hadoop)、RDMS/SQL或 Coli/ OLAP。
·数据库可使用各种工具访问和处理, 包括 AquaFold、专门报告、工作流调度、ETL 和数据库集成。同时, Cloudera Distribution for Hadoop 可对数据实施各种操作。
·处理过的数据使用专为工厂应用设计的Revolution Analytics 工具进行进一步分析。
·这些数据在易于理解的仪表盘中向用户展示。
经验总结和结论
英特尔使用物联网网关,借助从英特尔自身制造网络和设备及传感器提取的数据,集成并验证了大数据分析内部服务器解决方案,从而证实了物联网对于制造业的出色业务价值。采用了三菱电机 MELSEC-Q 系列 C 语言控制器。试点计划的实施有赖于工厂工程师、IT 部门和来自 Cloudera、戴尔、三菱电机和 Revolution Analytics 的行业专家的通力合作。团队首先采用现有机器性能和监控数据,然后使用大数据分析和建模功能获取用于预测潜在偏移和故障的数据。机器组件故障预测功能可支持工程师修复并防止偏移,从而通过避免浪费生产部件、缩短维修时间和减少机器备件使用量节约大量资金。
使用了大数据分析服务器和物联网网关上各种软件构建模块的集成套件。尚未开始利用制造数据中包含的智能优势的制造商,可以应用并实施此框架。已经使用数据提升效率的制造商可以进一步增强现有能力,以提高数据挖掘和分析能力。
对于英特尔而言,此试点计划预计每年可节约数百万美元,并能够带来更高的投资回报。优势包括延长设备组件正常运行时间、最小化良品和次品错误分类(从而提高产能和生产力),支持预测维护,同时减少组件故障。英特尔的制造环境和设备中还有多种其他类型的参数、度量法、产品和设备数据(结构化和非结构化),可以通过挖掘和分析这些数据获取新的业务价值。通过利用这一机会,英特尔将能够进一步提高工厂的效率和生产力,建立出色竞争优势。









